Deviance (statistics)
In statistics, deviance is a quality of fit statistic for a model that is often used for statistical hypothesis testing.
Contents |
Definition
The deviance for a model M0, based on a dataset y, is defined as[1]
![D(y) = -2 [\log \lbrace p(y|\hat \theta_0)\rbrace -\log \lbrace p(y|\hat \theta_s)\rbrace ].\,](/2012-wikipedia_en_all_nopic_01_2012/I/5f419873604dd1766381d38a967396a0.png)
Here 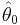 denotes the fitted values of the parameters in the model M0, while
denotes the fitted values of the parameters in the model M0, while 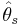 denotes the fitted parameters for the "full model": both sets of fitted values are implicitly functions of the observations y. Here the full model is a model with a parameter for every observation so that the data are fitted exactly. This expression is simply −2 times the log-likelihood ratio of the reduced model compared to the full model. The deviance is used to compare two models - in particular in the case of generalized linear models where it has a similar role to residual variance from ANOVA in linear models.
denotes the fitted parameters for the "full model": both sets of fitted values are implicitly functions of the observations y. Here the full model is a model with a parameter for every observation so that the data are fitted exactly. This expression is simply −2 times the log-likelihood ratio of the reduced model compared to the full model. The deviance is used to compare two models - in particular in the case of generalized linear models where it has a similar role to residual variance from ANOVA in linear models.
Suppose in the framework of the GLM, we have two nested models, M1 and M2. In particular, suppose that M1 contains the parameters in M2, and k additional parameters. Then, under the null hypothesis that M2 is the true model, the difference between the deviances for the two models follows an approximate chi-squared distribution with k-degrees of freedom.[1]
Some usage of the term "deviance" can be confusing. According to Collett:[2]
- "the quantity
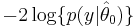 is sometimes referred to as a deviance. This is [...] inappropriate, since unlike the deviance used in the context of generalized linear modelling, does not measure deviation from a model that is a perfect fit to the data."
is sometimes referred to as a deviance. This is [...] inappropriate, since unlike the deviance used in the context of generalized linear modelling, does not measure deviation from a model that is a perfect fit to the data."
See also
- Pearson's chi-squared test, an alternative quality of fit statistic for generalized linear models.
- Akaike information criterion
- Deviance information criterion
- Peirce's criterion
- Discrepancy function
Notes
References
- McCullagh, Peter; Nelder, John (1989). Generalized Linear Models, Second Edition. Chapman & Hall/CRC. ISBN 0412317605.
- Collett, David (2003). Modelling Survival Data in Medical Research, Second Edition. Chapman & Hall/CRC. ISBN 1-58488-325-1.
External links
- Generalized Linear Models - Edward F. Connor
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||